I am a second-year DPhil student (generously funded by Clarendon Scholarship) at Oxford VGG, supervised by Prof. Andrea Vedaldi and Dr. Iro Laina. I also work closely with Dr. Chuanxia Zheng and Dr. Diane Larlus. My research interests mainly lie in the intersection between computer vision and computer graphics, especially in 3D vision.
During my master study at ETH Zürich, I did a research project on 3D human reconstruction, supervised by Chen Guo, Dr. Jie Song, and Prof. Otmar Hilliges. Also, I finished my master thesis “DNF-Avatar: Distilling Neural Fields for Real-time Animatable Avatar Relighting” under the supervision of Shaofei Wang and Prof. Siyu Tang. Prior to ETH, I did my bachelor’s at Beihang University. I was lucky to work with Prof. Si Liu.
I am always happy to collaborate and discuss research with others. So feel free to contact me!
We propose Mesh4D, a feed-forward model for monocular 4D mesh reconstruction. Given a monocular video of a dynamic object, our model reconstructs the object’s complete 3D shape and motion, represented as a deformation field. Our key contribution is a compact latent space that encodes the entire animation sequence in a single pass. This latent space is learned by an autoencoder that, during training, is guided by the skeletal structure of the training objects, providing strong priors on plausible deformations. Crucially, skeletal information is not required at inference time. The encoder employs spatio-temporal attention, yielding a more stable representation of the object’s overall deformation. Building on this representation, we train a latent diffusion model that, conditioned on the input video and the mesh reconstructed from the first frame, predicts the full animation in one shot. We evaluate Mesh4D on reconstruction and novel view synthesis benchmarks, outperforming prior methods in recovering accurate 3D shape and deformation.
From Rays to Projections: Better Inputs for Feed-Forward View Synthesis
Zirui Wu, Zeren Jiang, Martin Oswald, and Jie Song
In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2026
Feed-forward view synthesis models predict a novel view in a single pass with minimal 3D inductive bias. Existing works encode cameras as Plücker ray maps, which tie predictions to the arbitrary world coordinate gauge and make them sensitive to small camera transformations, thereby undermining geometric consistency. In this paper, we ask what inputs best condition a model for robust and consistent view synthesis. We propose projective conditioning, which replaces raw camera parameters with a target-view projective cue that provides a stable 2D input. This reframes the task from a brittle geometric regression problem in ray space to a well-conditioned target-view image-to-image translation problem. Additionally, we introduce a masked autoencoding pretraining strategy tailored to this cue, enabling the use of large-scale uncalibrated data for pretraining. Our method shows improved fidelity and stronger cross-view consistency compared to ray-conditioned baselines on our view-consistency benchmark. It also achieves state-of-the-art quality on standard novel view synthesis benchmarks.
DNF-Avatar: Distilling Neural Fields for Real-time Animatable Avatar RelightingOral
Zeren Jiang, Shaofei Wang, and Siyu Tang
In Proceedings of International Conference on Computer Vision Findings (ICCV Findings), Oct 2025
Creating relightable and animatable human avatars from monocular videos is a rising research topic with a range of applications, e.g. virtual reality, sports, and video games. Previous works utilize neural fields together with physically based rendering (PBR), to estimate geometry and disentangle appearance properties of human avatars. However, one drawback of these methods is the slow rendering speed due to the expensive Monte Carlo ray tracing. To tackle this problem, we proposed to distill the knowledge from implicit neural fields (teacher) to explicit 2D Gaussian splatting (student) representation to take advantage of the fast rasterization property of Gaussian splatting. To avoid ray-tracing, we employ the split-sum approximation for PBR appearance. We also propose novel part-wise ambient occlusion probes for shadow computation. Shadow prediction is achieved by querying these probes only once per pixel, which paves the way for real-time relighting of avatars. These techniques combined give high-quality relighting results with realistic shadow effects. Our experiments demonstrate that the proposed student model achieves comparable relighting results with our teacher model while being 370 times faster at inference time, achieving a 67 FPS rendering speed.
Geo4D: Leveraging Video Generators for Geometric 4D Scene ReconstructionHighlight
Zeren Jiang, Chuanxia Zheng, Iro Laina, Diane Larlus, and 1 more author
In Proceedings of International Conference on Computer Vision (ICCV), Oct 2025
We introduce Geo4D, a method to repurpose video diffusion models for monocular 3D reconstruction of dynamic scenes. By leveraging the strong dynamic prior captured by such video models, Geo4D can be trained using only synthetic data while generalizing well to real data in a zero-shot manner. Geo4D predicts several complementary geometric modalities, namely point, depth, and ray maps. It uses a new multi-modal alignment algorithm to align and fuse these modalities, as well as multiple sliding windows, at inference time, thus obtaining robust and accurate 4D reconstruction of long videos. Extensive experiments across multiple benchmarks show that Geo4D significantly surpasses state-of-the-art video depth estimation methods, including recent methods such as MonST3R, which are also designed to handle dynamic scenes.
MultiPly: Reconstruction of Multiple People from Monocular Video in the Wild Oral
Zeren Jiang*, Chen Guo*, Manuel Kaufmann, Tianjian Jiang, and 3 more authors
In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2024
We present MultiPly, a novel framework to reconstruct multiple people in 3D from monocular in-the-wild videos. Reconstructing multiple individuals moving and interacting naturally from monocular in-the-wild videos poses a challenging task. Addressing it necessitates precise pixel-level disentanglement of individuals without any prior knowledge about the subjects. Moreover, it requires recovering intricate and complete 3D human shapes from short video sequences, intensifying the level of difficulty. To tackle these challenges, we first define a layered neural representation for the entire scene, composited by individual human and background models. We learn the layered neural representation from videos via our layer-wise differentiable volume rendering. This learning process is further enhanced by our hybrid instance segmentation approach which combines the self-supervised 3D segmentation and the promptable 2D segmentation module, yielding reliable instance segmentation supervision even under close human interaction. A confidence-guided optimization formulation is introduced to optimize the human poses and shape/appearance alternately. We incorporate effective objectives to refine human poses via photometric information and impose physically plausible constraints on human dynamics, leading to temporally consistent 3D reconstructions with high fidelity. The evaluation of our method shows the superiority over prior art on publicly available datasets and in-the-wild videos.
HEAD: HEtero-Assists Distillation for Heterogeneous Object Detectors
Luting Wang, Xiaojie Li, Yue Liao, Zeren Jiang, and 4 more authors
Conventional knowledge distillation (KD) methods for object detection mainly concentrate on homogeneous teacher-student detectors. However, the design of a lightweight detector for deployment is often significantly different from a high-capacity detector. Thus, we investigate KD among heterogeneous teacher-student pairs for a wide application. We observe that the core difficulty for heterogeneous KD (hetero-KD) is the significant semantic gap between the backbone features of heterogeneous detectors due to the different optimization manners. Conventional homogeneous KD (homo-KD) methods suffer from such a gap and are hard to directly obtain satisfactory performance for hetero-KD. In this paper, we propose the HEtero-Assists Distillation (HEAD) framework, leveraging heterogeneous detection heads as assistants to guide the optimization of the student detector to reduce this gap. In HEAD, the assistant is an additional detection head with the architecture homogeneous to the teacher head attached to the student backbone. Thus, a hetero-KD is transformed into a homo-KD, allowing efficient knowledge transfer from the teacher to the student. Moreover, we extend HEAD into a Teacher-Free HEAD (TF-HEAD) framework when a well-trained teacher detector is unavailable. Our method has achieved significant improvement compared to current detection KD methods. For example, on the MS-COCO dataset, TF-HEAD helps R18 RetinaNet achieve 33.9 mAP (}}+2.2}}+2.2), while HEAD further pushes the limit to 36.2 mAP (}}+4.5}}+4.5).
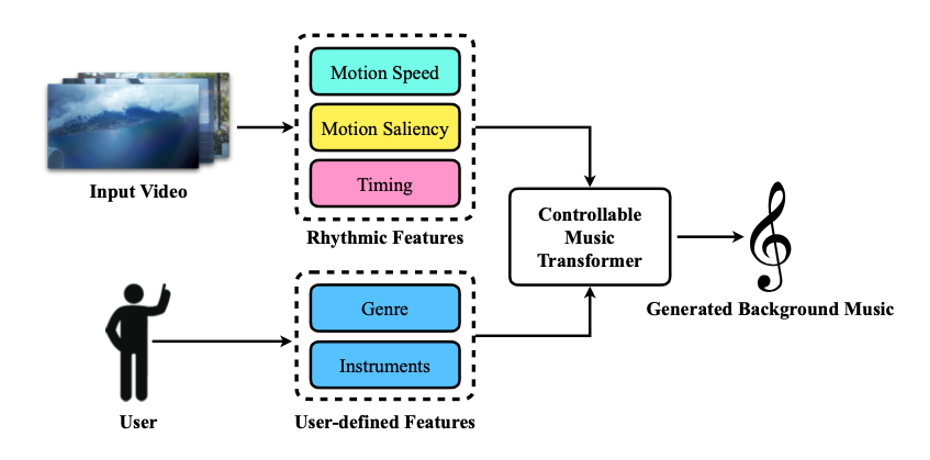
Video Background Music Generation with Controllable Music Transformer Best Paper Award
Shangzhe Di*, Zeren Jiang*, Si Liu, Zhaokai Wang, and 4 more authors
In Proceedings of the 29th ACM International Conference on Multimedia, Oct 2021
In this work, we address the task of video background music generation. Some previous works achieve effective music generation but are unable to generate melodious music specifically for a given video, and none of them considers the video-music rhythmic consistency. To generate the background music that matches the given video, we first establish the rhythmic relationships between video and background music. In particular, we connect timing, motion speed, and motion saliency from video with beat, simu-note density, and simu-note strength from music, respectively. We then propose CMT, a Controllable Music Transformer that enables the local control of the aforementioned rhythmic features, as well as the global control of the music genre and the used instrument specified by users. Objective and subjective evaluations show that the generated background music has achieved satisfactory compatibility with the input videos, and at the same time, impressive music quality.
General Instance Distillation for Object Detection
Xing Dai*, Zeren Jiang*, Zhao Wu, Yiping Bao, and 3 more authors
In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2021
In recent years, knowledge distillation has been proved to be an effective solution for model compression. This approach can make lightweight student models acquire the knowledge extracted from cumbersome teacher models. However, previous distillation methods of detection have weak generalization for different detection frameworks and rely heavily on ground truth (GT), ignoring the valuable relation information between instances. Thus, we propose a novel distillation method for detection tasks based on discriminative instances without considering the positive or negative distinguished by GT, which is called general instance distillation (GID). Our approach contains a general instance selection module (GISM) to make full use of feature-based, relation-based and response-based knowledge for distillation. Extensive results demonstrate that the student model achieves significant AP improvement and even outperforms the teacher in various detection frameworks. Specifically, RetinaNet with ResNet-50 achieves 39.1% in mAP with GID on COCO dataset, which surpasses the baseline 36.2% by 2.9%, and even better than the ResNet-101 based teacher model with 38.1% AP.

 Video Background Music Generation with Controllable Music Transformer Best Paper AwardIn Proceedings of the 29th ACM International Conference on Multimedia, Oct 2021
Video Background Music Generation with Controllable Music Transformer Best Paper AwardIn Proceedings of the 29th ACM International Conference on Multimedia, Oct 2021



